The Edge-Native Inference Gateway: Turning Unpredictable AI Opex into Fixed, Predictable Cost
For infrastructure leaders. How an inference-native routing gateway on hardware you own converts metered, unbounded cloud-inference spend into capex-based, predictable cost — without giving up capability, safety, latency, or data control. Written for the industrial edge.
Abstract
Metered cloud inference is the fastest-growing and least predictable line in many enterprise AI budgets: cost scales with every token, every retry, and every agent loop, and the bill arrives after the spend is already committed. We argue that for the industrial edge — factories, depots, substations, vehicles, regulated sites — the durable answer is an edge-native inference gateway: own the silicon, run the models on-prem, and put a single inference-native gateway in front of them that decides which model handles each request, reuses cached computation, sends only the context a turn needs, and enforces safety and policy inline. This converts a variable opex stream into a fixed capex plus near-electricity marginal cost, makes spend predictable and bounded, keeps data on-premises, and removes the cloud round-trip. We describe the architecture for the CTO, the cost model for the infrastructure VP, the four token-economics levers that bend the curve, a three-year TCO comparison, and a deployment blueprint on owned reference hardware.
1The unpredictable-opex problem
AI moved from a pilot line item to a production dependency, and the bill followed. The trouble is not only that it is large — it is that it is unbounded and arrives in arrears.
Metered inference prices the wrong thing for an operator. You are billed per token, so cost scales with prompt length, retries, multi-turn agent loops, tool output pasted back into context, and traffic you do not control. A single agent that "thinks harder" or re-reads a large document can multiply the cost of an outcome by 10× with no change in business value. Budgets are set annually; token spend compounds daily. The result is a line item that finance cannot forecast and infrastructure cannot cap.
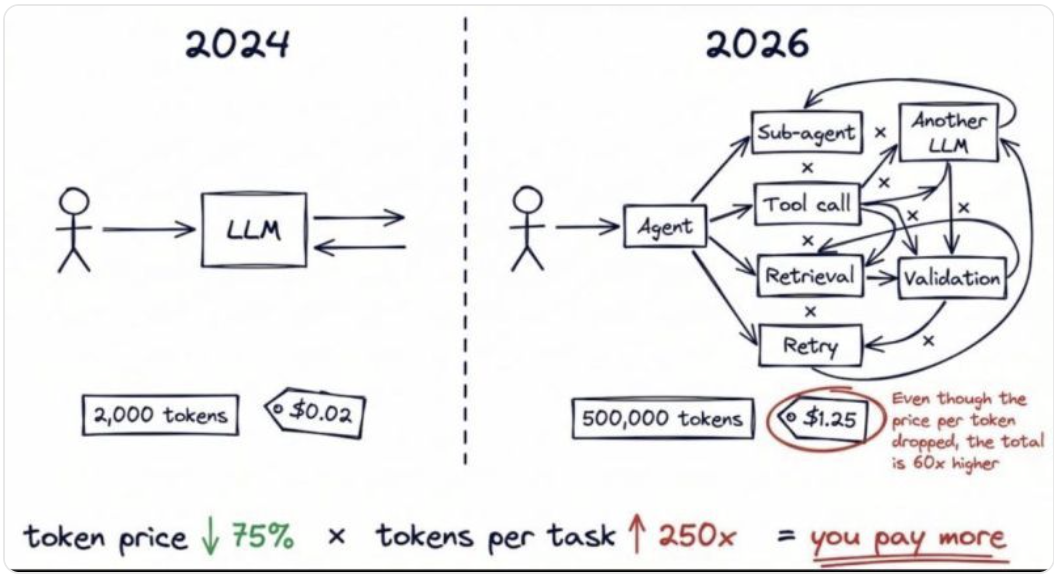
For the industrial edge three more constraints stack on top of cost:
- Data gravity and sovereignty. Telemetry, video, control logs and process data are large, sensitive, and often regulated. Shipping them to a cloud model is a governance liability and an egress bill.
- Latency and availability. A line, a vehicle or a substation cannot wait on a round-trip to a region, and cannot stop when the link does.
- Determinism. Operations need the same answer, at the same latency, at the same cost — not a number that drifts with a vendor's pricing or capacity.
Stop renting inference by the token for steady-state industrial workloads. Own the silicon, run the models where the data is, and govern every request through one gateway — so cost becomes capex you control, not opex you discover.
2Architecture: the edge-native inference gateway
The gateway is not a proxy bolted in front of a model. It is the control point where workload, routing, serving, caching and policy meet — designed from the inference engine out, not around it.
Every request enters through one routing contract: signals become projections, projections drive a decision, and the decision chooses the model — across a mesh of local small models, on-prem large models, and (only when it genuinely pays) an external frontier API. The same gateway protects reusable computation, trims context to the evidence a turn needs, and runs safety and policy inline. Because it is co-designed with a high-throughput, memory-efficient serving engine, it follows the engine's optimization rules instead of treating every call as generic chat traffic.
3Why edge-native — the CTO view
Edge-native is an architectural choice before it is a cost choice. It changes where data lives, where decisions happen, and what you can guarantee.
| Property | Cloud-metered inference | Edge-native gateway on owned silicon |
|---|---|---|
| Data path | Sensitive data egresses to a third party | Data stays on-prem; nothing leaves the boundary |
| Latency | Region round-trip + queue, variable | Local, deterministic, sub-network |
| Availability | Depends on the link and the vendor | Runs through link and provider outages |
| Sovereignty | Subject to external jurisdiction & retention | Wholly within your governance domain |
| Reversibility | Vendor sets pricing, models, deprecations | You version, shadow-test and revert policy |
| Cost shape | Variable opex, billed in arrears | Fixed capex + near-electricity marginal cost |
The gateway is what makes "edge-native" operationally real rather than a pile of GPUs. It gives one place to set
policy, one place to meter spend, one OpenAI- and Anthropic-compatible ingress so applications do not change, and one
lifecycle (shadow → activate → revert) so routing never drifts silently. Capability is not
sacrificed: hard requests still reach a large on-prem model, and the rare request that truly needs a frontier model
can still take that path — by exception, under policy, with the cost attributed.
4Four token-economics levers
Owning the silicon caps the denominator (you stop paying per token). The gateway shrinks the numerator — the work each outcome actually costs — with four compounding levers.
| Lever | Mechanism | Effect on cost-per-outcome |
|---|---|---|
| Signal-driven routing | Each request is classified by intent, complexity, risk and modality; mechanical and easy turns go to small local models, and reasoning is invoked only when it pays. | Routed paths run at a small fraction of an always-large path |
| Prefix-cache discipline | Stable prompt prefixes, deterministic tool schemas and bounded, append-only context keep reusable prefixes intact across a long session. | Cached tokens are reused at a steep discount instead of recomputed every turn |
| Context selection | The gateway sends the evidence a turn needs — selected, bounded and compressed — rather than pasting whole documents and tool dumps. | Large reductions in prompt and tool-output tokens, with continuity preserved |
| Semantic caching | Semantically-equivalent requests reuse a prior answer instead of triggering fresh inference. | Repeat and near-repeat traffic costs nothing to serve |
5The economics — the Infra-VP view
The job is not to minimize this month's invoice; it is to make next year's number knowable. Edge-native does that by changing the shape of the cost curve.
Metered inference is a line that rises with usage and never flattens; every new agent, every longer prompt, every retry adds to it forever. Owned capacity is a step (the purchase) followed by a nearly flat line (power, space, maintenance). Past a modest, steady utilization the two curves cross — and beyond the crossover, every additional unit of work on owned silicon is effectively free relative to the meter.
6Reference hardware on owned silicon
Predictable economics need predictable units. Two complementary, commodity-priced platforms cover the develop-and-serve lifecycle on hardware you keep on your floor.
NVIDIA DGX Spark — the on-prem development & large-model node
A GB10 Grace Blackwell desktop supercomputer with 128 GB of coherent unified memory and roughly 1,000 TFLOPS (FP4) of AI compute — enough to prototype, fine-tune and serve models up to ~200B parameters locally, or ~405B across a linked pair over its built-in high-speed fabric. It runs the same container stack as the datacenter, so what you build here promotes to the edge unchanged.
AMD Ryzen AI Max+ 395 — the private inference node
A small, all-metal node fusing 16 Zen 5 cores, a Radeon 8060S iGPU and an XDNA 2 NPU for ~126 TFLOPS of platform AI, with 128 GB of LPDDR5X-8000 — enough to keep 70B-class models resident and private. Dual 10GbE and dual USB4 let nodes cluster into a compute hub, so capacity scales by adding fixed-price units, not by raising a meter.
7A three-year TCO comparison
An illustrative model for a single industrial site running a steady mix of copilots, vision triage and maintenance queries. Figures are directional — the point is the shape, not a quote.
| Dimension | Metered cloud inference | Edge-native gateway (owned) |
|---|---|---|
| Upfront capex | ~$0 | One-time node fleet + setup (depreciable, resaleable) |
| Recurring cost | Per-token bill that grows with usage, retries and context | Power, space, maintenance, support — roughly flat |
| Marginal cost of +1 request | Full token price, every time | Approaches electricity once capacity exists |
| Data egress | Per-GB transfer for telemetry, video, documents | None — data never leaves the site |
| Budget predictability | Forecast error grows with adoption | Known within power and capacity envelopes |
| 3-year trajectory | Rises every quarter; no natural ceiling | Step at year 0, near-flat thereafter |
| Exit / change cost | Re-platform on vendor pricing & deprecations | Hardware retained; policy versioned and reversible |
For steady-state industrial workloads, edge-native turns "how much will AI cost next year?" from a forecast into a capacity-planning question — the same discipline you already apply to compute, storage and network.
8Industrial edge use cases
| Use case | Why edge-native | Primary saving |
|---|---|---|
| Vision QC on the line | High-rate video can't egress; needs sub-second local decisions | No egress; small-model routing on repetitive frames |
| Predictive maintenance | Continuous sensor streams, mostly normal; rare anomalies | Cache + cheap path for normal; reserve large model for anomalies |
| OT / IT security | Detection must run in the data path, on-prem, always-on | Local inference; no telemetry leaves the boundary |
| Field & control-room copilots | Repetitive shift queries; must work offline and fast | High cache & small-model hit rates; predictable cost |
| Regulated document & agent automation | Sensitive records can't be sent to third-party models | Sovereignty; context selection trims long-document tokens |
9Deployment blueprint
- Develop on the large node. Prototype, fine-tune and evaluate on the on-prem development supercomputer; keep models and data inside the boundary.
- Promote unchanged. Ship the same containers to a fleet of small edge inference nodes — one pipeline, one artifact, one cost basis.
- Front everything with the gateway. All traffic flows through one OpenAI- and Anthropic-compatible ingress that routes by signal, reuses prefixes, selects context, and enforces safety.
- Meter and attribute. Every route is logged with latency, tokens and cost, so spend is accountable per team and per workload — while the task runs, not after.
- Shadow, activate, revert. Test every routing or policy change on replayed traffic before activation, with one-click rollback.
- Scale by units, not by meter. Add fixed-price nodes to the cluster as demand grows; the cost curve stays a series of known steps.
10Governance, safety & reversibility
Owning the inference path is also the strongest governance posture available. Sensitive context never leaves the site, so leaked vectors and prompts handed to models you do not control — a business liability and a governance violation — simply cannot happen. Safety classifiers for sensitive-data leakage, prompt injection and unsafe output run inline on every turn, not as an afterthought. Tools and code execute in policy-governed sandboxes. And because the whole control plane is versioned, every change is shadow-tested and reversible — the opposite of a vendor deprecating a model under you.
11Recommendations & checklist
- Inventory steady-state workloads. Repetitive, high-volume, latency- or sovereignty-sensitive traffic is the first to move edge-native.
- Buy capacity, not tokens, for that traffic. Size a node fleet to steady demand; keep a frontier path for the long tail.
- Make the gateway the single ingress. One routing contract, one policy plane, one meter, compatible APIs so apps don't change.
- Turn on all four levers. Routing, prefix-cache discipline, context selection and semantic caching compound.
- Keep data on-prem by default. Treat egress as an exception that needs justification.
- Version and shadow-test policy. Never let routing drift silently; always be able to revert.
- Attribute cost continuously. Per-route metering turns AI spend into a capacity-planning input.
- Plan the two-tier fleet. Develop on the large node; serve on small nodes; promote artifacts unchanged.
12References
- NVIDIA (2026). DGX Spark — Personal AI Supercomputer (GB10 Grace Blackwell). 128 GB LPDDR5X coherent unified memory; ~1,000 TFLOPS FP4; high-speed fabric for linked-pair scaling.
- AMD (2026). Ryzen AI Max+ 395 (Strix Halo). 16 Zen 5 cores, Radeon 8060S iGPU, XDNA 2 NPU; ~126 platform AI TFLOPS; 128 GB LPDDR5X-8000.
- Workload–router–pool architecture for inference optimization (2026). Signal-driven routing across a mixture of models by cost, capability, privacy and risk.
- When-to-reason routing (2025). Invoking expensive reasoning paths only when expected value justifies the cost.
- Category-aware semantic caching for heterogeneous workloads (2025). Reusing answers for semantically-equivalent requests.
- Prefix / KV-cache reuse in high-throughput serving. Cached prompt prefixes billed at a steep discount versus recomputation.
- Inference-native agent harness practice (2026). Prefix-cache discipline, context selection and bounded tool output for long-horizon work.
- Unovie.AI. GPU EdgeGateway & Device Platform. unovie.ai/platform/gpu-edgegateway · unovie.ai/device-platform