Apple Intelligence
Apple Intelligence : On Device Processing
Edge-AI Privacy Innovation / Security Blueprint from Apple WWDC24 Conference
Apple WWDC24 Keynote has some amazing GENAI Edge Innovation and brilliant engineering science on display which they talked about how on-device models that can outsource to Apple’s servers. Most notable is their approach to features that don’t work with an on-device model.

Apple WWDC24 Keynote : Apple Intelligence Reference YouTube video at 1h14m43s
Apple-intelligence
When you make a request, Apple Intelligence analysis whether it can be processed on device. If it needs greater computational capacity, it can draw on Private Cloud Compute, and send only the data that’s relevant to your task to be processed on Apple Silicon servers.
Your data is never stored or made accessible to Apple. It’s used exclusively to fulfill your request. And just like your iPhone, independent experts can inspect the code that runs on the servers to verify this privacy promise.
In fact, Private Cloud Compute cryptographically ensures your iPhone, iPad, and Mac will refuse to talk to a server unless its software has been publicly logged for inspection.
This sets a brand new standard on Privacy and AI
Embracing Edge AI On-Device Inferencing: A Strategic Imperative for Enterprises
In today's rapidly evolving technological landscape, enterprises are increasingly recognizing the significance of Edge AI on-device inferencing as a key strategic initiative. The transition to Edge AI not only promises reduced operational expenses but also propels real-time decision-making capabilities. This shift is particularly pertinent given the limited access to high-end GPUs like the NVIDIA H100, which often ties enterprises into public cloud ecosystems, leading to skyrocketing operational expenditures (OPEX). Recent financial reports from NVIDIA and OpenAI echo this growing concern, underscoring the urgent need for cost-effective, yet powerful AI solutions.
The Demand for AI-Embedded Software
The burgeoning demand for AI-embedded software, such as Microsoft's Copilot+, has showcased the transformative potential of AI in enhancing user interactions and automating complex tasks. These advanced AI systems leverage Edge NPU (Neural Processing Units), TPU (Tensor Processing Units), and GPU (Graphics Processing Units) to optimize data formatting in near real-time—be it converting healthcare data into the FHIR format or standardizing payment data to ISO20022 benchmarks.
Addressing Edge NPU Constraints
A critical challenge lies in the power and device constraints associated with Edge NPUs. Traditional Intel processors fall short, particularly in maintaining battery efficiency. However, recent advancements in computing hardware are closing this gap. Apple’s M2 Pro and M3 chips have set new benchmarks in energy-efficient AI inferencing. Meanwhile, NVIDIA JetSon Orin, Qualcomm’s Snapdragon X Elite, AMD’s Ryzen AI, and Intel’s Gaudi3, alongside a suite of ARM processors, are pioneering the next generation of powerful and energy-efficient NPU edge computing solutions.
Real-Time Decisions in the Physical World
Edge AI’s potential shines brightest in real-world, real-time decision-making scenarios. Autonomous vehicles, for instance, rely on immediate safety decisions to protect passengers and pedestrians. In healthcare, an MRI scan identifying a brain hemorrhage can trigger an urgent alert to a surgical team, enhancing patient outcomes through timely interventions. Similarly, Apple’s Siri exemplifies how AI can process device-specific information to make optimal decisions on behalf of users. These examples underscore the criticality of GEN-AI models’ capability to operate both online and offline, ensuring seamless functionality in intermittently connected environments.
The Case for Distributed Tensor Mesh and Joint Inferencing
Standalone models, while beneficial, often fall short in complex, real-world environments. For example, a Tesla vehicle utilizes a collective feed from eight cameras to inform its autonomous driving decisions, ensuring a comprehensive understanding of its surroundings. In the medical sector, an MRI machine's on-edge computing power might only yield a 60% confidence level in detecting a condition. Thus, the DICOM images must be transmitted to a nearby GPU cloud, leveraging extensive computational resources to reach near-100% diagnostic confidence crucial for obtaining FDA Class III certification.
Technology
In the competition between open-source Large Language Models (LLMs) and closed models, a key benefit of open models lies in their ability to be run locally on your own hardware. Unlike closed models, which require access to external providers and incur additional costs beyond electricity and infrastructure expenses, open models offer greater flexibility and autonomy. Nevertheless, this advantage diminishes as model sizes grow, making it increasingly difficult to run massive models that demand substantial memory resources. Fortunately, emerging techniques such as tensor parallelism and distributed inference may help alleviate these scalability challenges
Matrix multiplication is the dominant computation in Large Language Models (LLMs), accounting for approximately 97-98% of all computations. Fortunately, this operation is highly parallelized across multiple CPU/GPU cores and devices, making it an ideal candidate for distributed computing. By dividing the matrix multiplication among multiple devices, each device can perform a portion of the calculation, resulting in a significant speedup. For example, if a single device can compute the matrix multiplication in n seconds, two devices can complete it in n/2 seconds. This is known as tensor parallelism.
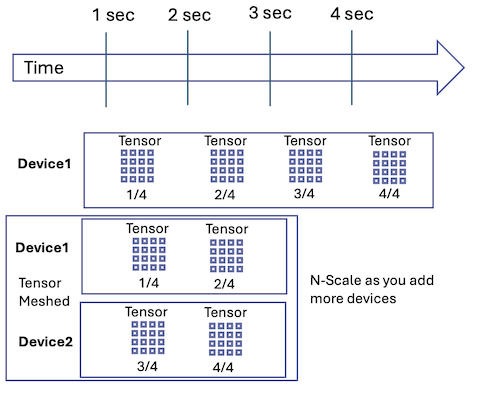
While tensor parallelism shows great promise for speeding up LLM inference, there's a catch: synchronization between devices is a major bottleneck. While we can accelerate the matrix multiplication, we must eventually synchronize the neural network state across devices, which takes time. The speed of synchronization depends on the communication links between devices. Professional AI clusters often employ high-speed interconnects like NVLink, We at Unovie are using USB3.1 Gen1 Interconnects achieving (5 Gbps).
However, there's a surprising twist: when designed with optimization in mind, the amount of data required to synchronize LLMs can be remarkably low. For instance, a quantize version of the Llama 3 8B model (6.3 GB) requires only 1 MB of data to synchronize per token across two devices. This is an extremely small overhead.
This leads us to the concept of distributed NPU mesh networks, where multiple models collaboratively enhance decision-making accuracy. This approach parallels human decision-making processes, where collective input often results in more accurate outcomes. Implementing a collective quorum of decision-making models allows for higher reliability and precision, pivotal in mission-critical applications.

Trust : User Privacy
Trust of User Privacy is extremely important for every enterprise. Where it is HITRUST, FFIEC, FEDRAMP, NIST Standards. These security engineering privacy requirements should be the same every enterprise needs to adopt whether is Medical Device Manufacturer, Automotive EV Initiatives, HealthCare, Financial, Telecom Services, OTT providers Apple announcement is not too far from what GEHC has been working in MEDTECH world since last 4 years, Chief AI officer recently posted on Linkedin "GEHC Tops list for third year in row in highest number of AI-Enabled Medical Device Authorization"
Conclusion
Edge AI on-device inferencing represents a paradigm shift in enterprise strategy, promising enhanced real-time decision-making and cost efficiencies. The journey towards this vision involves embracing advanced NPU technologies, harnessing distributed inferencing models, and overcoming the limitations of traditional processors. With industry leaders like Apple, Qualcomm, AMD, and Intel setting new standards, the path towards a robust and cost-effective Edge AI ecosystem is clearer than ever.
For enterprises, the strategic imperative is now to integrate these cutting-edge AI technologies into their core operations, driving innovation while safeguarding operational budgets. By doing so, businesses can unlock unprecedented levels of agility, accuracy, and efficiency, cementing their competitive edge in an increasingly AI-driven world.
Credits : Unovie.AI At Unovie.AI we strive to be your specialized professional AI partner, delivering unique AI solutions using our innovative private edge technology, the UnoVie platform. We offer engineering expertise and collaborate with partners to bring AI best practices to your organization. By leveraging your internal domain expertise, we create value-driven outcomes within predictable timelines. We complement your resources and build extremely reliable, safety critical AI systems with explain-ability and transparency. We adhere to strict data privacy and regulatory AI security requirements. Our core strengths lie in MedTech, BioSciences, Pharma and Industrial Automation use cases.Learn more about us at https://unovie.ai.