GPT Vision Transformer
Vision AI in Healthcare: Streamlining Processes and Empowering Decisions
Let's explores the transformative potential of Vision AI, specifically Vision GPT, in revolutionizing healthcare operations.
Understanding Vision GPT
Vision GPT is a powerful pre-trained model that seamlessly integrates computer vision and natural language processing (NLP). It leverages a transformer architecture to analyze both visual and textual data simultaneously, unlocking a deeper understanding of the relationship between them.

While existing large vision models excel in transfer learning, they often struggle when faced with various tasks and simple instructions. The challenge lies in handling spatial hierarchy and semantic granularity inherent in diverse vision-related tasks.
Key challenges include the limited availability of comprehensive visual annotations and the absence of a unified pretraining framework with a singular neural network architecture seamlessly integrating spatial hierarchy and semantic granularity. Existing datasets tailored for specialized applications heavily rely on human labeling, which limits, the development of foundational models capable of capturing the intricacies of vision-related tasks.
Vision Models
Phi-3-Vision-128K-instruct
Microsoft recently released Phi-3, a powerful language model, with a new Vision-Language variant called Phi-3-vision-128k-instruct. This 4B parameter model achieved impressive results on public benchmarks, even surpassing GPT-4V in some cases and outperforming Gemini 1.0 Pro V in all but MMMU.
FaceBook-Chmeleon Chameleon 🦎 by Meta is a unique model: it attempts to scale early fusion 🤨 But what is early fusion? Modern vision language models use a vision encoder with a projection layer to project image embeddings so it can be promptable to text decoder (LLM)
Early fusion on the other hand attempts to fuse all features together (image patches and text) by using an image tokenizer and all tokens are projected into a shared space, which enables seamless generation 😏 Authors have also introduced different architectural improvements (QK norm and revise placement of layer norms) for scalable and stable training and they were able to increase the token count (5x tokens compared to Llama 3 which is a must with early-fusion IMO)
This model is an any-to-any model thanks to early fusion: it can take image and text input and output image and text, but image generation are disabled to prevent malicious use.
One can also do text-only prompting, authors noted the model catches up with larger LLMs (like Mixtral 8x7B or larger Llama-2 70B) and also image-pair prompting with larger VLMs like IDEFICS2-80B
Florence-2
Florence-2 is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of vision and vision-language tasks. Florence-2 can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. It leverages our FLD-5B dataset, containing 5.4 billion annotations across 126 million images, to master multi-task learning. The model's sequence-to-sequence architecture enables it to excel in both zero-shot and fine-tuned settings, proving to be a competitive vision foundation model.
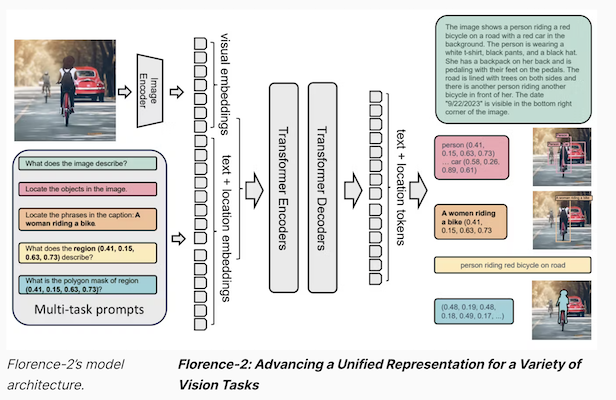
Built by Microsoft, the Florence-2 model adopts a sequence-to-sequence architecture, integrating an image encoder and a multi-modality encoder-decoder. This design accommodates a spectrum of vision tasks without the need for task-specific architectural modifications, aligning with the ethos of the NLP community for versatile model development with a consistent underlying structure.
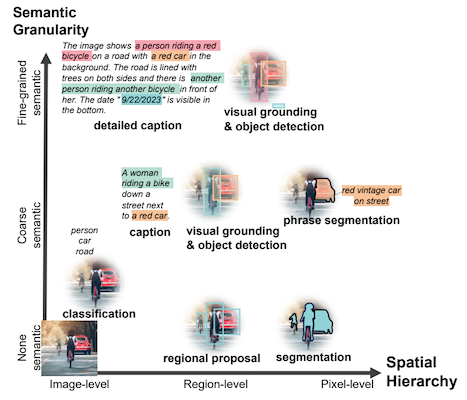
Florence-2 stands out through its unprecedented zero-shot and fine-tuning capabilities, achieving new state-of-the-art results in tasks such as captioning, object detection, visual grounding, and referring expression comprehension. Even after fine-tuning with public human-annotated data, Florence-2 competes with larger specialist models, establishing new benchmarks.
Key Capabilities:
Object Recognition: Identifies objects within images (e.g., medical equipment, tumors, handwritten notes) using convolutional neural networks (CNNs) and transformer models.

Semantic Understanding: Connects visual concepts with corresponding words or phrases, accurately interpreting descriptions of scenes and objects.

Contextual Reasoning: Analyzes the context surrounding objects in images, discerning nuances often missed by traditional computer vision models.

Transforming Healthcare Processes
Vision GPT's unique capabilities offer significant benefits across various healthcare domains:
Streamlined Data Ingestion:
- Vision GPT can process complex medical documents like bills containing handwritten notes, extracting crucial information like dates, provider details, and disputed items.
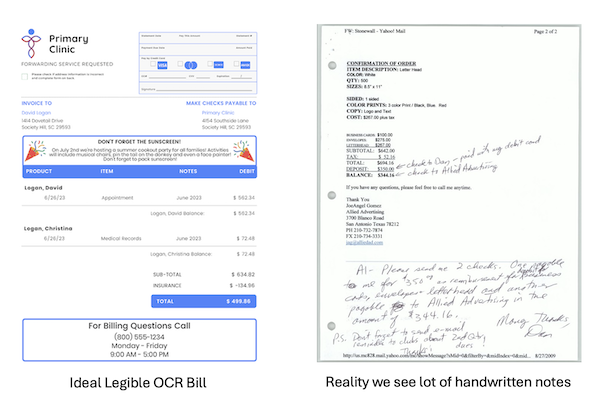
- This automated data extraction reduces manual effort and improves accuracy in pre-authorization and post-authorization processes.
Enhanced Bill Review:
-
Vision GPT can analyze medical bills, matching line items with medical codes, descriptions, and insurance policies.
-
It identifies covered services, deductibles, and potential discrepancies, streamlining the payment process and reducing errors.
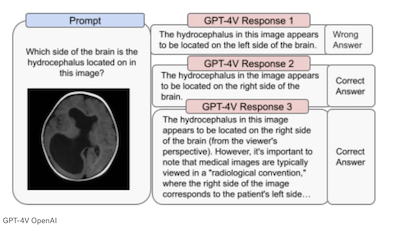
Improved Patient Care: * Vision GPT can assist in analyzing medical images, aiding radiologists in detecting abnormalities and supporting faster, more accurate diagnoses.
Addressing Concerns and Ensuring Success
Model Maturity: Utilize Vision GPT models specifically pre-trained on healthcare and billing related datasets for optimal performance.
Trust and Control:
- Avoid relying solely on public API only accessable generic models.
- Prioritize deploying models locally and pretrain them with customer specific data to ensure complete control over features, versions and expected behavior.
- Have strong Pen-Testing Capabilities built in to ensure these models cannot be comprimised by hidden OCR messages which are not visible to human, but will effect the automated decisions upstream.
Conclusion
Vision GPT holds immense promise for transforming healthcare by automating complex processes, improving accuracy, and empowering data-driven decision-making.
By addressing concerns and implementing best practices, healthcare organizations can leverage this powerful technology to enhance patient care, streamline operations, and ultimately achieve better outcomes.
Credits : Unovie.AI is a specialized professional AI partner company with its unique UnoVie platform. We closely collaborate with our partners, leveraging their internal domain expertise to create value-driven outcomes within predictable timelines. We complement resources and design reliable, critical systems with explainability and transparency, adhering to strict privacy and regulatory security requirements. Our core strengths lie in MedTech and Industry 4.0 use cases. Learn more about us at https://unovie.ai.
References Phi-3-Vision Fine-Tuning-Small-Vision-Model