The NVIDIA, Qualcomm and AMD platforms we build, optimize and operate end-to-end — from a power-efficient far-edge processor to a desktop AI supercomputer. The same Unovie stack, your data, on silicon you own.
A Blackwell-class edge supercomputer for physical AI. NVIDIA Jetson AGX Thor packs up to 2,070 FP4 TFLOPS of generative-AI compute and 128 GB of unified memory into a power-configurable module small enough to live inside a robot, a vehicle or a machine — running several large models, vision and multi-sensor fusion at once, on-prem. We build, optimize and operate the full Unovie stack on Thor, so your edge agents run where the data is born.
Thor ships as a compact, fan-cooled edge node: a dense I/O wall of USB, networking, display and capture, with a Blackwell GPU and 128 GB of unified memory behind it. Mount it on the line, in the cab or at the cell — and run the models where the data is born.

A datacenter-class Blackwell GPU with FP4 and a transformer engine, packed into a module — generative and vision models that used to need a rack now run inside the machine.
A 14-core Arm Neoverse CPU and high-bandwidth memory run camera, lidar, radar and language models together, fused in real time for autonomy and inspection.
MIG carves the GPU into isolated slices inside a configurable 40–130W envelope, with a functional-safety design for robots and autonomous machines.
Image Thor with the Unovie edge stack.
Local models + Nexus context, on-device.
Vision, sensors and agents reason live.
Closed-loop control, fully on-prem.
2,560 CUDA cores and next-gen Tensor Cores with FP4 and a transformer engine for on-device generative AI.
A 14-core Arm Neoverse-V3AE cluster feeds the GPU and runs the control plane, sensors and OS.
High-speed camera, networking and PCIe lanes ingest many sensors at once with deterministic latency.
A petaFLOP AI supercomputer that fits on a desk. NVIDIA DGX Spark pairs the GB10 Grace Blackwell Superchip with 128 GB of coherent unified memory and up to 1,000 TFLOPS of FP4 compute — enough to prototype, fine-tune and run models up to ~200B parameters locally, or ~405B across a linked pair. We run it as your private development and inference node: the full Unovie stack, your data, your room.
Spark is a desktop-sized chassis with a perforated cooling top and a full I/O wall — a GB10 Grace Blackwell Superchip and 128 GB of coherent memory inside. Develop, fine-tune and serve large models locally; promote them to the edge unchanged.

A 20-core Arm Grace CPU and a Blackwell GPU joined by NVLink-C2C share one coherent memory space — no PCIe copies between CPU and GPU.
Unified LPDDR5X holds models up to ~200B parameters; two units linked over ConnectX scale to ~405B — inference and fine-tuning without the cloud.
Runs NIM microservices, CUDA frameworks and the same containers as DGX in the datacenter — develop locally, deploy to the edge unchanged.
Prototype & fine-tune locally on Spark.
Wire in your Nexus context and data.
Run the same containers as production.
Ship unchanged to edge or MicroCloud.
Grace CPU and Blackwell GPU on one package, joined by NVLink-C2C at chip-to-chip bandwidth.
CPU and GPU address one coherent pool — no host-device copies, and room for ~200B-parameter models.
ConnectX networking links two Sparks into a single ~405B-parameter inference target.
A power-efficient edge-AI processor for robots, cameras and handhelds. The Qualcomm QCS6490 pairs an octa-core Kryo CPU, an Adreno GPU and a Hexagon AI processor for up to 12 TFLOPS — multi-camera vision and on-device models on a fanless, battery-friendly power budget, with Wi-Fi 6E and long industrial lifecycle support. We bring the Unovie stack to it, so intelligence runs at the far edge, on hardware you own.
QCS6490 reference hardware brings a full I/O wall — USB-C, USB 3.0, dual Ethernet, 10GbE and HDMI — to a compact, fanless box. Premium-tier on-device AI without the power bill, deployed where wires and watts are scarce.

Up to 12 TFLOPS from the Hexagon processor with a fused tensor accelerator — vision, speech and sensor models on a budget that fits a fanless box or a battery.
A Spectra triple ISP ingests up to five concurrent cameras with computer-vision hardware — multi-camera perception for robots, handhelds and smart cameras.
FastConnect Wi-Fi 6E and Bluetooth 5.2 keep the edge connected wirelessly, with wide-temperature, long-lifecycle industrial availability.
Up to 5 cameras and sensors stream in.
Kryo CPU + Adreno GPU + Hexagon NPU.
Vision and language models on-device.
Results over Wi-Fi 6E, no cloud.
A 6 nm octa-core Qualcomm Kryo CPU runs the OS, control and classical workloads beside the AI engines.
The Hexagon processor with a fused tensor accelerator and the Adreno GPU share inference and graphics — up to 12 TFLOPS.
A triple ISP captures up to five concurrent camera streams with 4K HDR video and on-sensor computer vision.
A private AI server in a small metal box. The AMD Ryzen AI Max+ 395 fuses 16 Zen 5 CPU cores, a Radeon 8060S iGPU and a next-gen XDNA 2 NPU for 126 platform AI TFLOPS, paired with 128 GB of LPDDR5X-8000 — enough to run 70B-class models locally, behind dual 10GbE and USB4 so nodes cluster into a compute hub. We deploy the Unovie stack on it for secure, private inference on hardware you own.
An all-metal chassis with a built-in 230 W supply exposes dual 10GbE, dual USB4 and fast PCIe 4.0 NVMe on its I/O wall — a quiet, durable node you can rack a few of, or set one on a desk.
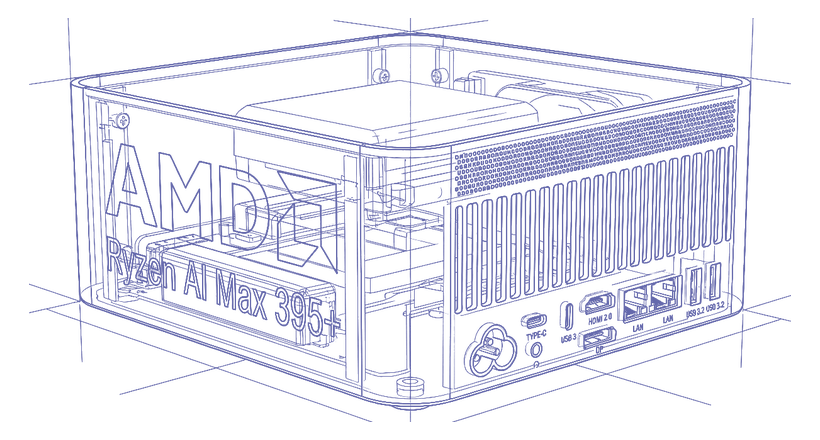
Sixteen Zen 5 CPU cores, a Radeon 8060S iGPU and a next-gen XDNA 2 NPU combine for 126 AI TFLOPS — CPU, GPU and NPU inference in one package.
128 GB of LPDDR5X-8000 keeps large models — 70B-class and up — resident and private, with no weights leaving the box.
Dual 10GbE and dual USB4 at 40 Gbps link nodes into an AI compute hub for distributed, local inference.
70B-class models resident in 128 GB.
CPU + Radeon iGPU + XDNA 2 NPU.
Link nodes over 10GbE / USB4.
Private inference, fully on-prem.
A 16-core Zen 5 CPU drives orchestration, data prep and classical workloads alongside inference.
The Radeon 8060S iGPU and XDNA 2 NPU share AI work for 126 TFLOPS across vision, language and agents.
Dual turbine fans and a full-coverage vapor chamber sustain 140 W at about 32 dB — full performance, near silence.
Turnkey Edge-AI — fixed time, fixed cost, full responsibility.